


1. 使用Adobe Acrobat Reader提取图片
Adobe Acrobat Reader是一款广泛使用的PDF阅读器,它提供了基本的图片提取功能。以下是使用Adobe Acrobat Reader提取图片的步骤:
步骤1:打开Adobe Acrobat Reader,导入需要提取图片的PDF文件。
步骤2:在页面缩略图中,找到包含所需图片的页面。
步骤3:点击页面缩略图,进入页面查看模式。
步骤4:在页面查看模式下,点击图片,然后选择“另存为…”选项。
步骤5:在弹出的对话框中选择保存位置,为图片命名,并点击“保存”按钮。
步骤6:等待图片保存完成后,即可在指定位置找到提取的图片。
2. 使用启源PDF转换器
启源PDF转换器是一款专业的PDF转换工具。它支持PDF、Word、PPT、Excel、图片等文件的批量互转,新增PDF合并、压缩、拆分、 加密、解密、页面提取、图片提取功能,采用OCR文字识别技术精准度更高,速度更快。
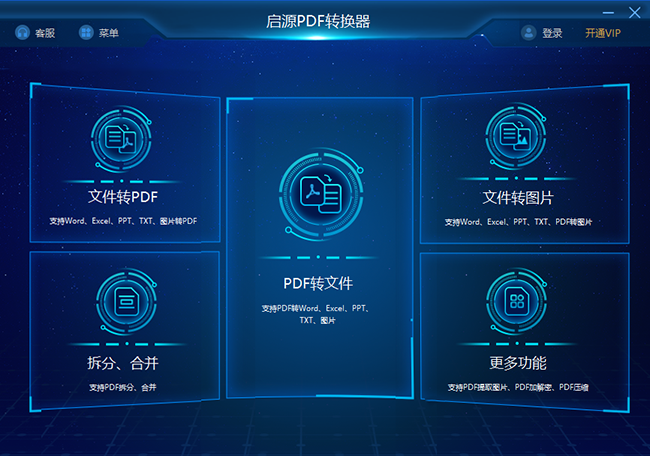
步骤1:运行软件启源PDF转换器。
步骤2:选择提前图片功能(步骤:更多功能——PDF提取图片);
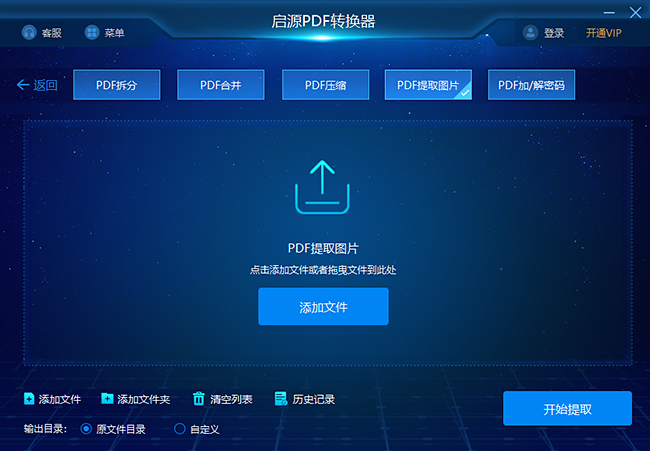
步骤3:上传需要提前图片的PDF文件;
步骤4:设置相关菜单(如:输出格式、输出目录等)
步骤5:点击“开始提取”按钮,等待完成即可。
3.使用在线工具提取图片
除了Adobe Acrobat Reader,还有一些在线工具可以帮助我们提取PDF文件中的图片。以下是一个简单易用的在线工具:
步骤1:在浏览器中输入在线工具的网址,进入网站。
步骤2:上传需要提取图片的PDF文件。

步骤3:选择图片输出格式(如JPG、PNG等)。
步骤4:设置图片质量(可选)。
步骤5:点击“提取”按钮,开始提取图片。
步骤6:提取完成后,下载包含图片的压缩文件。
步骤7:解压压缩文件,即可获得提取的图片。
4. 使用编程语言提取图片
如果您具备编程基础,可以使用Python等编程语言来实现PDF图片的自动提取。这里以Python为例,介绍一种使用Python库PDFPlumber提取PDF文件中图片的方法:
步骤1:安装PDFPlumber库,可以使用pip命令安装:
pip install pdfplumber
步骤2:编写Python脚本,实现图片提取功能。
python
import pdfplumber
import os
# PDF文件路径
pdf_path = "example.pdf"
# 图片保存路径
image_path = "output_images"
# 创建图片保存目录
if not os.path.exists(image_path):
os.makedirs(image_path)
# 打开PDF文件
with pdfplumber.open(pdf_path) as pdf:
# 遍历PDF中的每一页
for page in pdf.pages:
# 提取当前页面的图片
images = page.images
for img in images:
# 获取图片的矩形边界
x0, y0, x1, y1 = img.bbox
# 提取图片数据
img_data = page.within_bbox([x0, y0, x1, y1]).to_image()
# 保存图片
img_path = os.path.join(image_path, f"image_{len(os.listdir(image_path))}.png")
img_data.save(img_path)
print("图片提取完成")
步骤3:运行Python脚本,提取PDF文件中的图片。
通过以上三种方法,您可以轻松提取PDF文件中的图片。根据您的需求和实际情况,选择合适的方法进行操作。希望本文能为您提供帮助!
 立即下载
立即下载 丢失数据恢复教程
丢失数据恢复教程

